July 15, 2025
Windows Event Viewer in the Browser
For the last weekend hacking I decided to pursue an old interest. I maintain an EVTX parser in Rust and have always wanted to plug it into some kind of WASM context.
Since it's now possible to just vibe things I thought it would be a nice idea to create a Windows Event Viewer clone that runs entirely in the browser — with some extra filtering tricks.
We ended up with:
- Logs streaming from parsing EVTX → DuckDB via IPC in Arrow, all in the browser.
- Classy Windows-style UI elements in React.
- Some surprising filtering prowess.
#Initial mock-up
For those of you who aren't familiar with the Windows Event Viewer, it's this lovely interface:
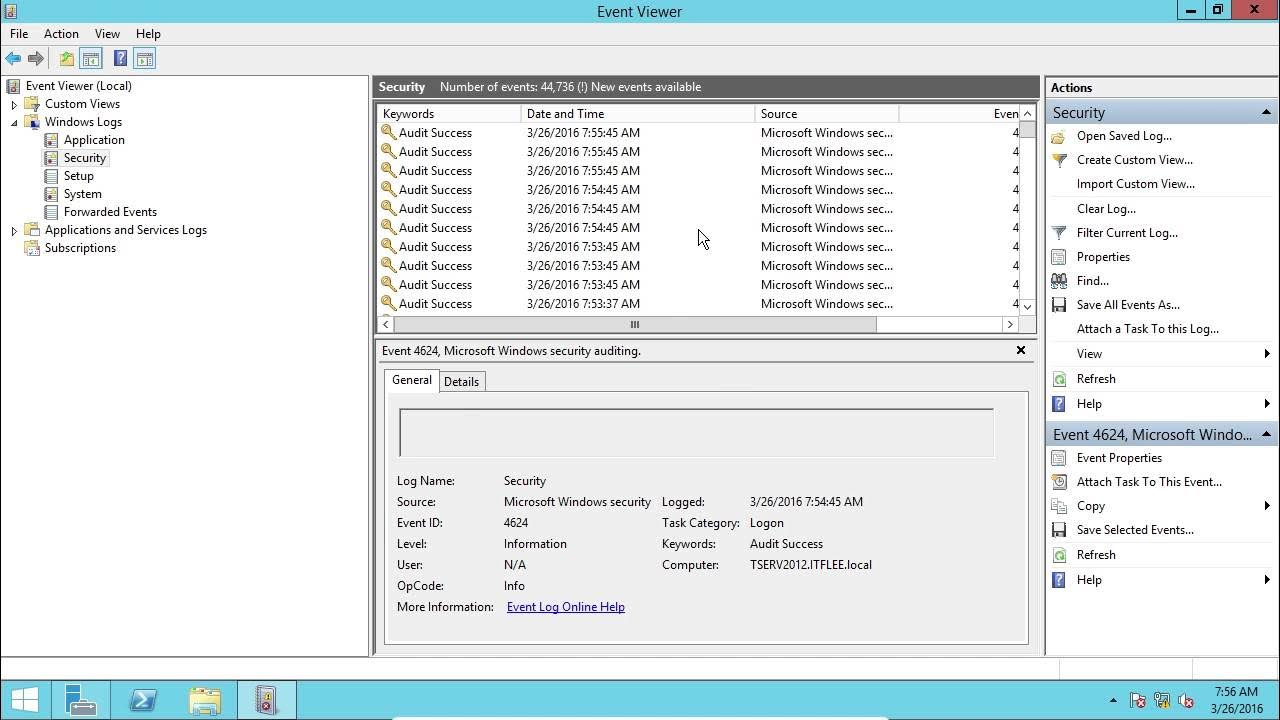
Armed with that screenshot I vibe-coded a React-based clone. When I asked for Windows aesthetics the models pulled a Windows 11 icon kit, so the result kind of looks like this:
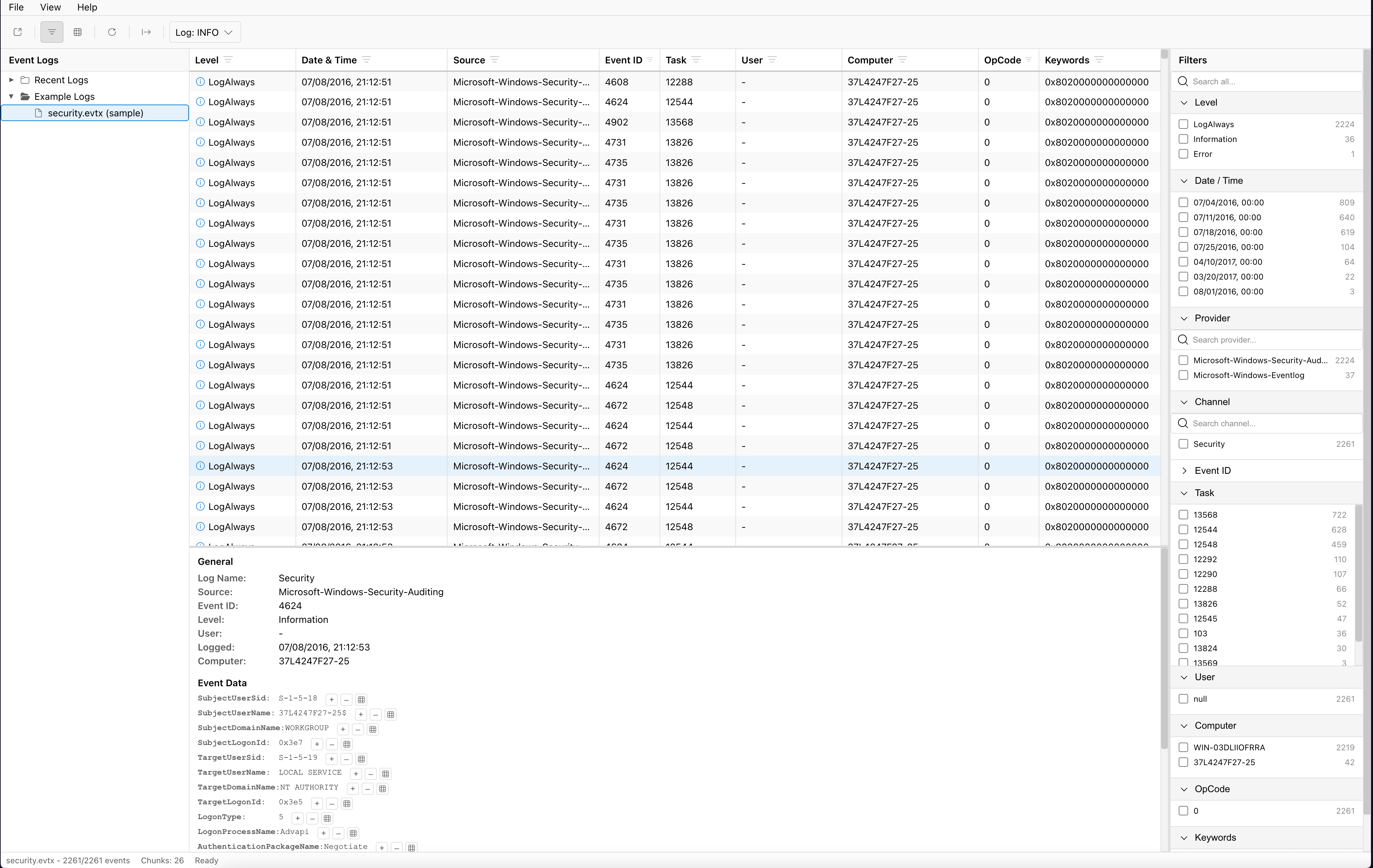
I also replaced the sidebar (right) with a facet-counting (à la Datadog) widget while keeping the native Windows feel.
Starting initially I added a naïve set of bindings that would basically load the entire file into memory and convert it into a JavaScript object:
#[wasm_bindgen]
pub fn parse_all(&self) -> Result<JsValue, JsError> {
let cursor = Cursor::new(&self.data);
let mut parser = EvtxParser::from_read_seek(cursor)?
.with_configuration(settings);
let mut records = Vec::new();
for record in parser.records_json_value() {
if let Ok(record_data) = record {
records.push(record_data.data);
}
}
let result = ParseResult {
total_records: records.len(),
records,
// ...
};
serde_wasm_bindgen::to_value(&result)
}The table itself is using @tanstack/virtual — a no-brainer if we want to scroll tens of thousands of logs and keep the DOM from imploding.
In the first version we kept all of the parsed records in memory but not in the DOM. This actually worked quite well for less than 1 million records 🙂
#Virtualisation & lazy loading
But alas, the void calls — why waste all this precious memory? EVTX files are stored in chunks of 64 KB, each independently parsable. Perhaps we could load the file chunk-by-chunk and hook into virtualisation to lazily parse the chunks. That would be neat.
export class LazyEvtxReader {
private parser: EvtxWasmParser;
private cache: Map<string, EvtxRecord[]> = new Map();
async getWindow(win: ChunkWindow): Promise<EvtxRecord[]> {
const key = `${win.chunkIndex}-${win.start}-${win.limit}`;
if (this.cache.has(key)) {
return this.cache.get(key)!;
}
const res = this.parser.parse_chunk_records(
win.chunkIndex,
win.start,
win.limit
);
const records = res.records.map(r => this.mapToObject(r));
this.cache.set(key, records);
return records;
}
}const virtualizer = useVirtualizer({
count: chunkCount,
getScrollElement: () => containerRef.current,
estimateSize: (idx) => {
const recordCount = chunkRecordCounts[idx] ?? estimateRowsPerChunk;
return rowHeight * recordCount;
},
overscan: 2,
});
// Load visible chunks as the user scrolls
useEffect(() => {
virtualizer.getVirtualItems().forEach((item) => {
ensureChunk(item.index);
});
}, [virtualizer.getVirtualItems()]);With that we could scroll a bunch of logs and even implement basic filtering.
#Facet counting
However, the true potential of having a filtering UI is doing some facet statistics and manipulation.
When looking at event logs you usually want to trace sessions, find outliers, etc. For example, looking at an example log file, it's interesting to think about what the odd ones out are — the events that appear less frequently:
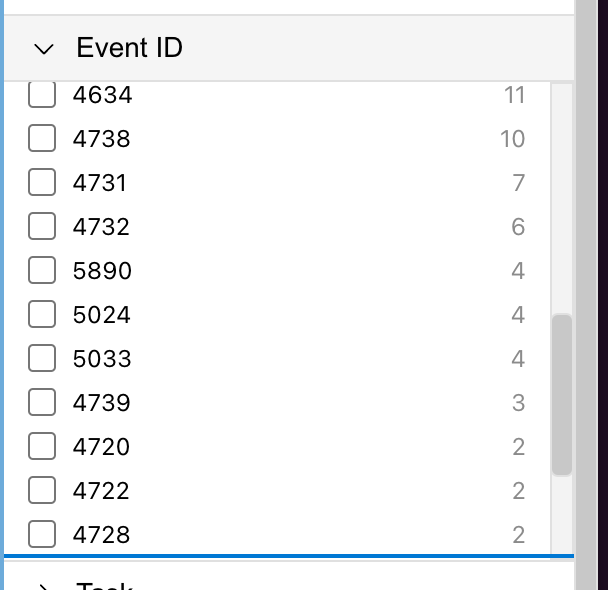
I implemented basic facet counting in Rust:
#[wasm_bindgen]
pub fn compute_buckets(data: &[u8]) -> Result<JsValue, JsError> {
let mut parser = EvtxParser::from_read_seek(Cursor::new(data))?;
let mut buckets = BucketCounts::default();
for record in parser.records_json_value() {
if let Ok(r) = record {
let sys = r.data.get("Event")
.and_then(|v| v.get("System"));
// Count by Level
if let Some(level) = sys.and_then(|s| s.get("Level")) {
*buckets.level.entry(level.to_string()).or_insert(0) += 1;
}
// Count by Provider
if let Some(name) = sys
.and_then(|s| s.get("Provider"))
.and_then(|p| p.get("Name")) {
*buckets.provider.entry(name.as_str().unwrap().to_owned()).or_insert(0) += 1;
}
// Similar for Channel & EventID...
}
}
serde_wasm_bindgen::to_value(&buckets)
}Playing with it revealed one problem: what if we apply a filter? That would render all the facet counts invalid. We could naïvely rescan the whole file — but that gets annoying with large logs.
We needed some kind of index — or actually a database.
#DuckDB to the rescue
DuckDB is an embedded analytics database, which means (in theory) we can load it into a browser tab, feed it the records and let it serve as an index so we can slice and dice our data.
Naïvely we could just insert the logs into DuckDB, but that creates overhead because we'd need to materialise all logs as TypeScript objects — essentially straining the browser by creating a ton of objects:
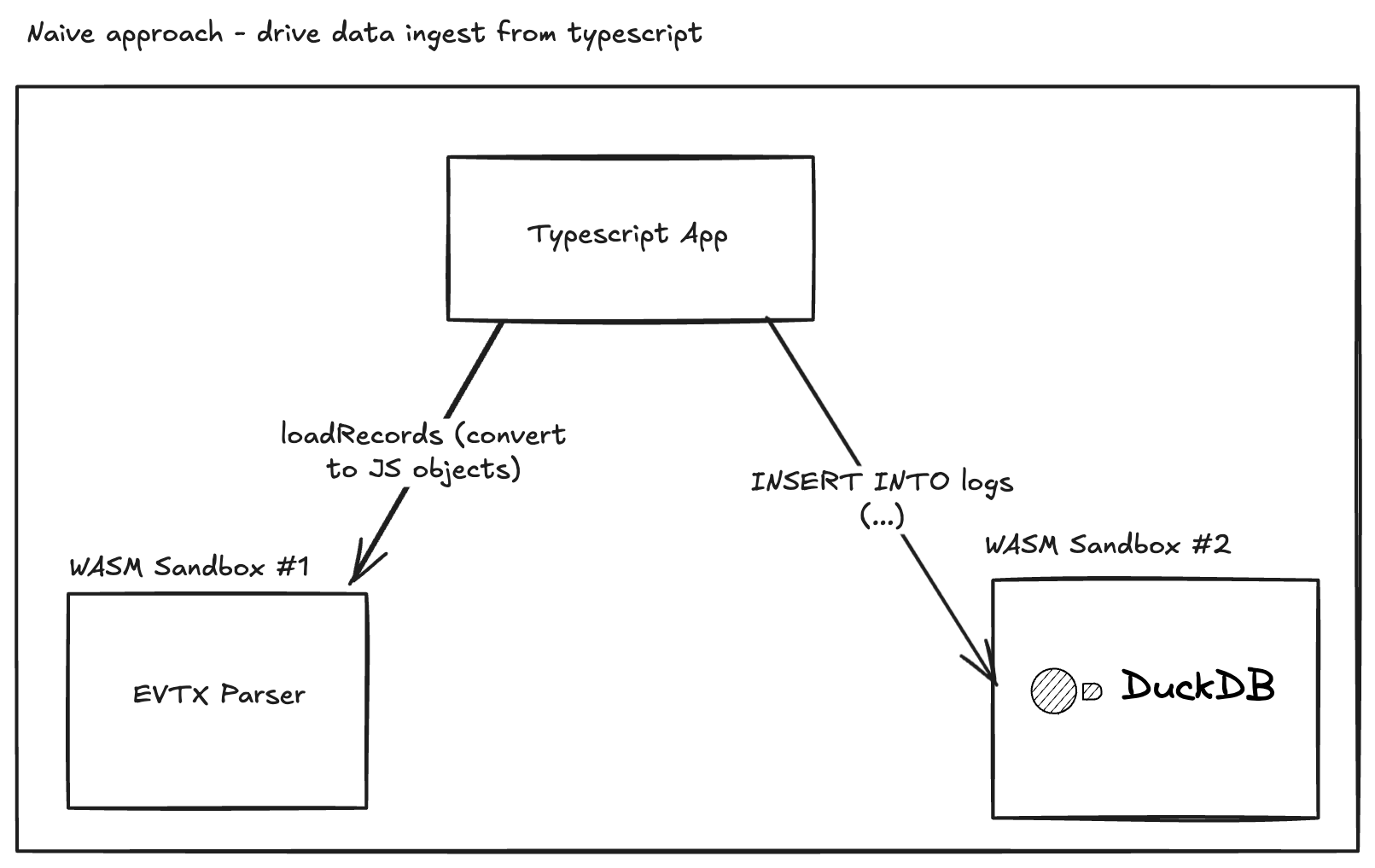
A neat optimisation is to have both WASM sandboxes communicate over IPC using Apache Arrow:
Here's how we serialise a chunk to Arrow IPC on the Rust side:
#[wasm_bindgen]
pub fn chunk_arrow_ipc(&self, chunk_index: usize) -> Result<ArrowChunkIPC, JsError> {
// Prepare column builders
let mut eid_builder = MutablePrimitiveArray::<i32>::new();
let mut level_builder = MutablePrimitiveArray::<i32>::new();
let mut provider_builder = MutableUtf8Array::<i32>::new();
let mut channel_builder = MutableUtf8Array::<i32>::new();
let mut raw_builder = MutableUtf8Array::<i32>::new();
// Parse the requested chunk
let chunk = self.get_chunk(chunk_index)?;
for record in chunk.records() {
let json = record.to_json();
// Extract fields and push to builders
eid_builder.push(extract_event_id(&json));
level_builder.push(extract_level(&json));
provider_builder.push(Some(extract_provider(&json)));
channel_builder.push(Some(extract_channel(&json)));
raw_builder.push(Some(json.to_string()));
}
// Create Arrow batch
let batch = Chunk::new(vec![
eid_builder.as_box(),
level_builder.as_box(),
provider_builder.as_box(),
channel_builder.as_box(),
raw_builder.as_box(),
]);
// Serialise to IPC format
let mut buf = Vec::new();
let mut writer = StreamWriter::new(&mut buf, WriteOptions { compression: None });
writer.start(&schema, None)?;
writer.write(&batch, None)?;
writer.finish()?;
Ok(ArrowChunkIPC { bytes: buf, rows: batch.len() })
}And on the TypeScript side, we consume it directly:
export async function startFullIngest(
reader: LazyEvtxReader,
onProgress?: (pct: number) => void
): Promise<void> {
const { totalChunks } = await reader.getFileInfo();
await initDuckDB();
for (let i = 0; i < totalChunks; i++) {
// Get Arrow IPC buffer from Rust
const { buffer } = await reader.getArrowIPCChunk(i);
// Feed directly to DuckDB
await insertArrowIPC(buffer);
onProgress?.((i + 1) / totalChunks);
// Let the UI breathe
await new Promise(r => requestAnimationFrame(r));
}
}
export async function insertArrowIPC(buffer: Uint8Array): Promise<void> {
const conn = await initDuckDB();
conn.insertArrowFromIPCStream(buffer, {
name: "logs",
append: true,
create: false,
});
}#Slice & dice
Virtualisation was a breeze to set up with DuckDB:
export async function fetchTabular(
columns: ColumnSpec[],
filters: FilterOptions,
limit = 100,
offset = 0
): Promise<Record<string, unknown>[]> {
const conn = await initDuckDB();
const select = columns.map(col =>
`${col.sqlExpr} AS "${col.id}"`
).join(", ");
const where = buildWhere(filters);
const query = `
SELECT ${select}, Raw
FROM logs
${where ? `WHERE ${where}` : ""}
LIMIT ${limit} OFFSET ${offset}
`;
return conn.query(query).toArray();
}We get all of our filtering applied server-side (sweet), which enables some really nice — and otherwise non-trivial — features:
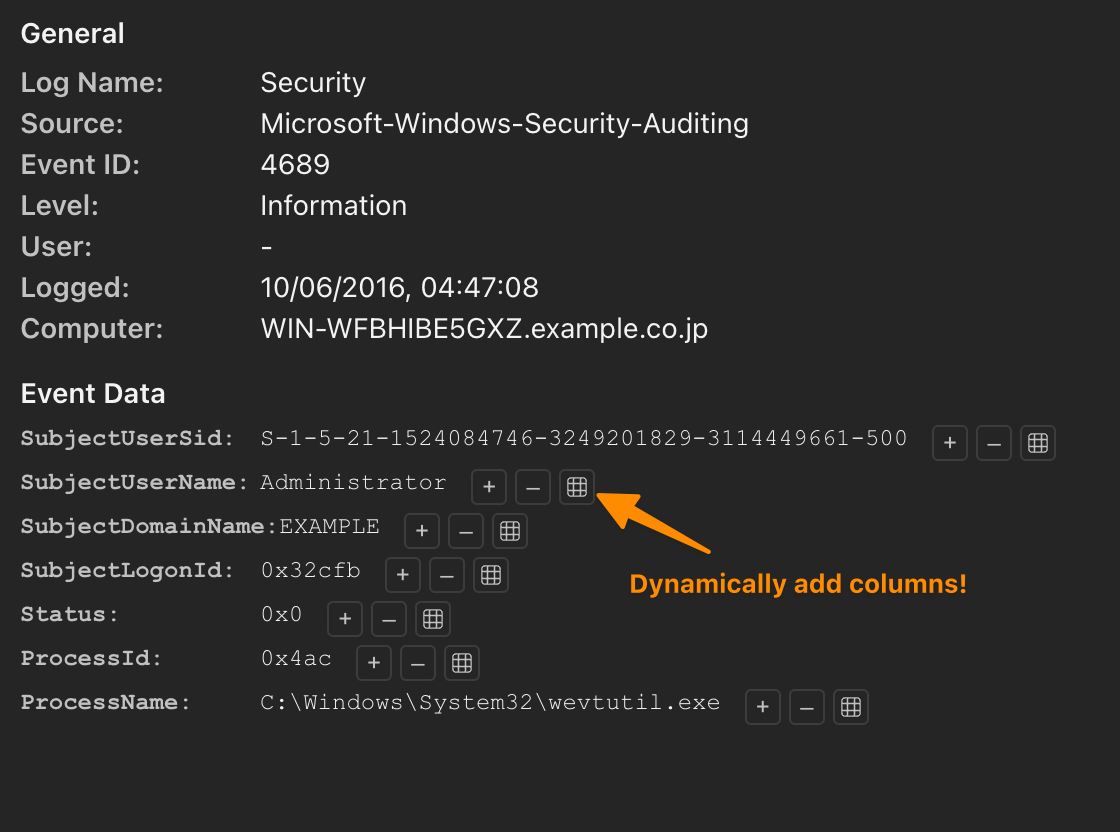
Internally it maps to something like:
// EventData field filtering using DuckDB's JSON functions
if (filters.eventData) {
for (const [field, values] of Object.entries(filters.eventData)) {
if (!values?.length) continue;
const valueList = values
.map(v => `'${escapeSqlString(v)}'`)
.join(",");
clauses.push(
`json_extract_string(Raw, '$.Event.EventData.${field}') IN (${valueList})`
);
}
}Everything runs quite a bit faster than I initially expected!
#Takeaways
The browser is a workhorse in 2025. It's an amazing way to distribute cross-platform apps, and they can be much more powerful than you'd expect.
This runs on every PC, is fully portable, requires no installation, no compilation. You could drop into an incident response scenario and whip this up from a Mac/Linux/PC/iPad.
Also, the fact that all sites look the same today is kind of a bummer — the dense UIs of the past feel much more effective than the airy ones we get everywhere now.
Hope one of you may find this useful one day!