August 15, 2025
GPT-5 goes hard on real-world programming
#Preface
For the last couple of days, I've spent millions of tokens (thanks Cursor + OpenAI!) vibe-benchmarking GPT-5. I've found it to be incredibly adept at actually writing code that solves issues end-to-end.
This post describes how I used GPT-5 to tackle a medium-sized problem: writing a parser for the EVTX format in Zig (EVTX is a binary format used for Windows Event Logs). I tried doing this with other models previously, and GPT-5 was the first model to actually get it over the finish line!
I think this is a cool problem because it's:
- Not too easy - you would need a few thousand lines of code to get something working.
- Not too hard: it's not as ambitious as writing a full "system," or something that would be 20k+ lines.
- Deterministic - there's a spec, and reference parsers.
- I've struggled with it, and I know which parts hurt.
I'll try to share the reasons why I think it did better than previous models I've attempted this with. If you only care about the result, it's actually in a usable state, and very performant, but for production, please use evtx.
TL;DR: GPT-5 wrote an entire parser for a rather complex binary format, and optimized it until it was faster than my carefully written Rust code (which was already the fastest in town)!
#My litmus test for a real life problem
I maintain evtx - a Rust-based EVTX parser I wrote years ago; it's still quite popular.
When I wrote it originally - I used the spec in the Windows XML Event Log (EVTX) documentation. The task I gave the model is rather straightforward:
- Take the spec - write a parser.
- While !parser output = Rust output, fix parser.
For sport, I withheld looking at the actual Rust code to see how well it could interpret the spec itself, but eventually I let the models peek at the code as well.
I wanted the LLM to write it in Zig because:
- I think Zig is an interesting technology for writing binary parsers.
- I don't want it to clone an implementation from another language from memory/web searches. Public implementations exist for Go/Python/C/C++, that it probably saw during training.
- I'm not very proficient in Zig, so I couldn't be arsed to write this myself, but I would definitely enjoy reading it and seeing how it fares.
- The parser doesn't need lots of external dependencies (Zig doesn't have a huge ecosystem).
- Zig is out-of-distribution for models (this is where all the smaller models/non-frontier ones basically perform terribly)
I've basically tried this task:
- When Sonnet 3.5 launched - failed (couldn't really debug stuff well)
- When o1/o1-pro launched - failed (tool use wasn't much of a thing back then, and you simply cannot one-shot this problem; the spec is too complex and models would get lazy)
- When Sonnet 3.7 launched - failed
- When Sonnet/Opus 4 launched using Claude Code ... failed (it was deceptively close, but could never debug itself out of the nuances of the parser)
- When OpenAI made o3 cheap and we could use it via Cursor ... failed (similar problems to Sonnet/Opus, but also was slower and more annoying to REPL)
All of these models succeeded at basic EVTX structures and binary parsing; they could even produce some partial results, but none could really get complete records.
GPT-5 is the first model to successfully write a full parser without me writing a single line of code. It was mostly me prompting it: "While !parser output = Rust output, fix parser."
#Why GPT-5 cooks
#GPT-5 produces minimal, viable edits
The biggest improvement: GPT-5 avoids "going to town" on the codebase. (Looking at you, Sonnet.) It favors a workflow that starts by gathering context - reading files, checking docs, thinking - then making changes. o3 also operated in a similar fashion, but this really takes it forward on all fronts. Compared to o3, it makes more focused, minimal edits; this compounds really well when producing code that will be edited later.
I would love to provide a concrete number, but I feel code produced by GPT-5 is about 30% of the lines compared to other models, and edits can sometimes be a single-line change (like a real person would!). I guess that some models (maybe like some people?) prefer append-only programming, where you make changes by adding more branches to the code, instead of restructuring it to accommodate new needs.
Sonnet/Opus are too "eager" to make edits, and IMO this causes them to write themselves into local maxima/minima from a certain codebase size/complexity.
#GPT-5 is a more steerable model
I found GPT-5 substantially better at following nuanced instructions, across its entire context/run length per session.
I explicitly instruct models to avoid "workarounds", "heuristics", and other garbage they reach for when they don't understand the issue. The spec is deterministic; yet when models fail to "grok" (pun intended) some nuance of the spec, they would write "I've added a fallback path that just randomly tries what I saw happen". This usually means things would go south from there, and more bugs will end up appearing.
Even when I repeated this instruction multiple times, other models kept doing this.
Models would be given this little ruleset:
# Heuristics
- If you think a heuristic is useful, then you are definitely wrong and this means we are taking a wrong approach.
- Format is fully deterministic. You MUST consider breaking out of local maxima in case you try to use heuristics.
- Try to avoid allocating "reasonable" amounts of memory. You should have information from the binary format to know how much memory to allocate.
- Many of the errors you will see are because we are interpreting wrong values as some other BinXML stuff, which can cause huge offsets and jumps, etc.GPT-5 gets it. It would even preempt or backtrack when it understands it's getting into these corners.
I saw publications use the term steerability; this makes a lot of sense to me.
#GPT-5 does significantly less "deception"
I actually think this is the number one reason I'm so excited about GPT-5.
At one point a bug slipped in during editing. I wanted to test my hunch more concretely. I created two separate Git worktrees of the repo and let Claude Code (Opus 4.1) and GPT-5-High duke it out on the same bug, with the same prompt and repo state.
Opus 4.1 wasn't even close, similar to my experience with it when I attempted to use it to write this.
"I've found the problem!" (it did not).

In general I found that Anthropic models:
- Rarely backtrack (i.e., this didn't improve; delete this code)
- Make edits that compromise the integrity of the code willy-nilly
- would delete tests/code paths when they want to "get it done" or that don't align with their hypothesis!
I ended up with partial records and a codebase full of garbage workarounds that basically skipped all the parsing that failed.
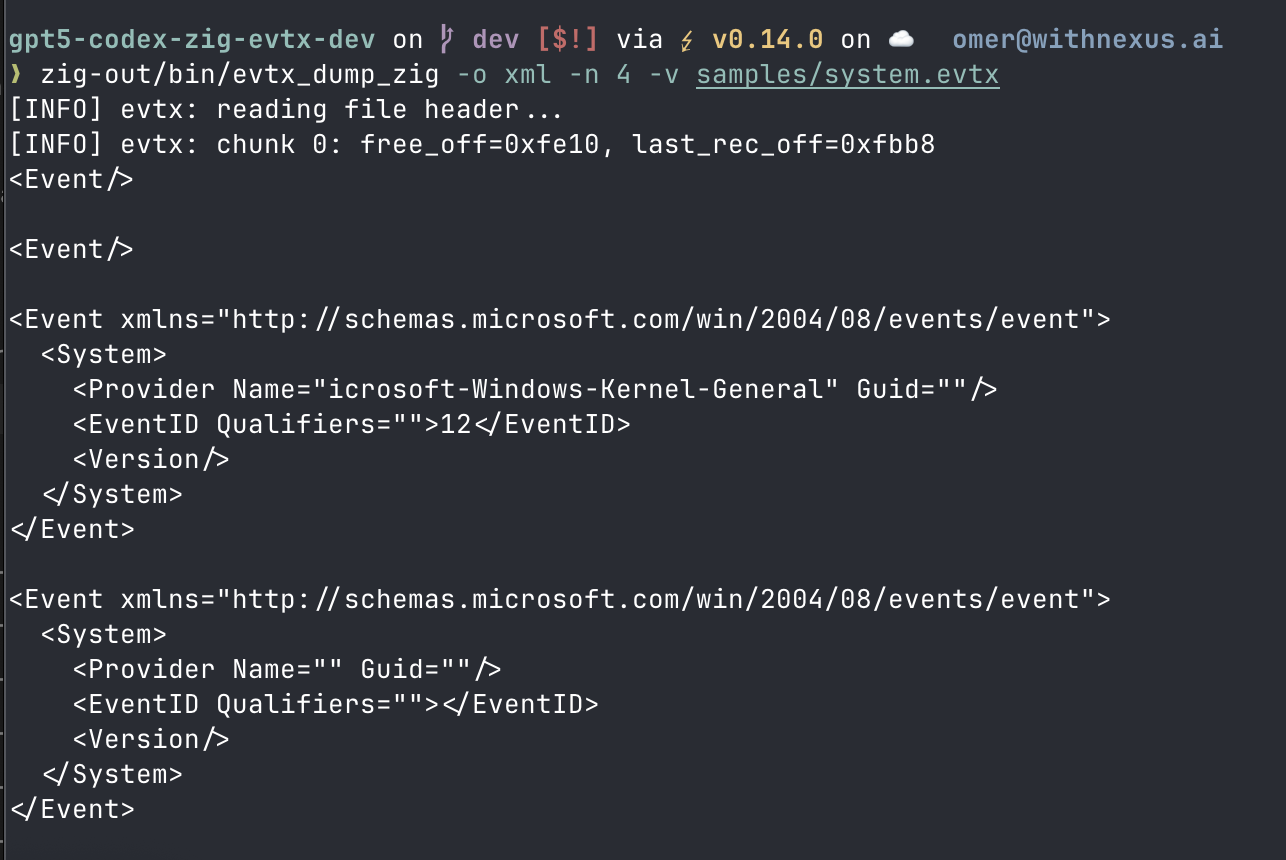
GPT-5 went on an entirely different kind of adventure. Instead it went on a thinking hike for 20-30 minutes (!) and spat out an accurate description of the bug, plus a few lines that produced almost-working records. From there I could pick it up and get to fully working.
#GPT-5 likes to work!
GPT-5 in Cursor is a workhorse. This thing RUNS. It would spend up to 40-50 minutes at a single prompt debugging, thinking, going back and forth with edits. I could go to lunch and back and it would still crunch things. This is a drastic change from how o3 behaves in Cursor - and I'm not sure it's solely due to recent Cursor improvements. I think the model is trained to work longer and focus on the output.
#EVTX complexity
EVTX parsing is nuanced. Parsers can fail in subtle ways and you end up with partial records.
We can break down the challenges into two:
#Micro level/Debugging
Debugging parser failures is really hard. Even slightly incorrect parsing logic produces complete garbage, so using only the output to debug, or trying to eyeball sources, is usually too hard to be practical (even for me!).
To reason about the problems one has to:
- introduce logs.
- break things into smaller parts.
- be able to interpret binary output and understand what is happening.
So logs + hexdump + spec are usually what one needs in context to understand why the parser suddenly crashed.
I did ask all models during the process to add logs when they debug, and create a logger that can toggle per-module verbosity to not overwhelm context.
All models struggle around EVTX templates, which is what makes the format a bit annoying.
The spec contains templates, which are recurring pieces of XML, and they would appear with different substitutions each time. This makes sense if you have a lot of logs that look basically the same, except they would have different process ids/user ids, etc.
This is what a template definition looks like:
TemplateDefinitionHeader
next_template_offset: 0x0012A3B0
guid: {7D6C8A6E-1F3B-4F0A-99B6-1B3E0A2D9C11}
data_size: 0x000001F4
[TEMPLATE DEFINITION] (List of tokens)
BinXML fragment tokens (shape with placeholders):
StartOfStream
FragmentHeader {major, minor, flags}
OpenStartElement "Event"
OpenStartElement "System"
OpenStartElement "Provider"
Attribute Name="Name" = Substitution(index=0, type=StringType, optional=false)
CloseStartElement / CloseElement
OpenStartElement "EventID"
Substitution(index=1, type=UInt16Type, optional=false)
CloseElement
OpenStartElement "TimeCreated"
Attribute Name="SystemTime" = Substitution(index=2, type=FileTimeType, optional=true)
CloseStartElement / CloseElement
CloseElement // System
OpenStartElement "EventData"
OpenStartElement "Data"
Substitution(index=3, type=StringType, optional=true)
CloseElement // Data
CloseElement // EventData
CloseElement // Event
EndOfStream
It would also provide the "substitution" tokens:
[SUBSTITUTION TOKEN FORMAT (inside the template)]
TemplateSubstitutionDescriptor {
substitution_index: u16 // zero-based
value_type: BinXmlValueType
ignore: bool // set during parsing if (optional && value_type == NullType)
}
And inside the binary stream we would see:
[TEMPLATE INSTANCE]
TemplateInstance {
_ignored: u8
_template_id: u32 // not used by the parser here
template_definition_data_offset: u32 -> points to the template above
number_of_substitutions: 4
}
// Descriptors (order = value order)
descriptors:
#0: { size: 0x0010, type: StringType, pad: 0x00 }
#1: { size: 0x0002, type: UInt16Type, pad: 0x00 }
#2: { size: 0x0008, type: FileTimeType, pad: 0x00 }
#3: { size: 0x0014, type: StringType, pad: 0x00 }
substitution_array (as tokens):
[0] Value(StringType("Service Control Manager"))
[1] Value(UInt16Type(7036))
[2] Value(FileTimeType(2025-08-01T10:22:33.123456Z))
[3] Value(StringType("The X service entered the running state."))
The parser could interpret some binary data as a length instead of a GUID, causing misalignment and eventually a crash.
For example, if we have:
Descriptors (correct):
#0: size=0x0010, type=BinaryType
#1: size=0x0002, type=UInt16Type
#2: size=0x0008, type=FileTimeType
Raw value bytes (hex) laid out sequentially:
// #0 BinaryType (16 bytes)
0000: 10 00 AA BB CC DD EE FF 11 22 33 44 55 66 77 88
// #1 UInt16 (2 bytes)
0010: B2 04
// #2 FileTime (8 bytes)
0012: 00 40 8B 07 D3 5D CF 01
// next token starts at 0x001A...
Correct interpretation:
- Read #0 as BinaryType: consume exactly 16 bytes (0x0000-0x000F).
- Read #1 as UInt16: 0x04B2 (1202) from bytes at 0x0010-0x0011.
- Read #2 as FileTime: bytes at 0x0012-0x0019 -> valid timestamp.
- Cursor ends at 0x001A (perfectly aligned for the next token).
Buggy interpretation (treat #0 as length-prefixed UTF-16 StringType):
- First two bytes `10 00` are misread as a count of UTF-16 code units: 0x0010 = 16 chars.
- Decoder now tries to read 32 bytes of string payload.
- But only 16 bytes were actually allocated for this field, so it swallows:
- the whole 16-byte binary (#0),
- PLUS the next 2-byte UInt16 (#1),
- PLUS the first 14 bytes of whatever comes after (in our case, it eats all 8 bytes of FileTime #2 and 6 bytes of the next structure).
- Cursor "lands" at 0x0030 instead of 0x0010/0x0012/0x001A.And the reason this happens is that strings are either length-prefixed or null-terminated, and that's context-dependent!
#Macro level/Architecture
To keep making progress, at some point it would be advisable to refactor the code into sort of an intermediate representation instead of trying to "naively" write the output during parsing. In general it's hard to refactor codebases, specifically ones that you didn't author fully (which is a problem when trying to have an agent get a task done end-to-end). So this essentially required the model to reason globally about all the code "at once".
Specifically, in this case it would also need to make idiomatic choices using Zig, and again I could only offer high-level advice to the agent, along with some reference code in another language. But concepts aren't always translatable verbatim.
It's hard to pin down why certain models simply write "better" code, can refactor and move stuff to places that make more sense, and then do so consistently.
#The results
They are in the Zig EVTX parser repository, and in the next post I will expand on how I prompted it to make the Zig code faster than the original implementation.
And also how I prompted my way to a 3x speedup for the Rust version!